Demystifying SQL Systems: To fetch or Not to Fetch
Understanding SQL at the fundamental level - because, in the end, it's all about having a healthy relationship with the Disk.

Before we move on to the fundamentals, let's eavesdrop on a conversation between two Senior Engineers and an Intern who are trying to debate which SQL database they should use for their next project.
Experienced Engineer 1 (EE1): "So, for our project, should we go with PostgreSQL or MySQL?"
Experienced Engineer 2 (EE2): "Ah, the eternal debate. I lean towards PostgreSQL for its advanced features and robustness."
EE1: "Really? I'm more inclined towards MySQL. It's fast and has a wide user base."
EE2: "Hey Intern, what do you think? Which one should we go ahead with?"
Intern: "I think we should use PostgreSQL for the project."
EE1: "Okay, that's a nice answer - will you also tell us why we should use this and not MySQL?"
Intern: "Well, PostgreSQL is better because its name starts with 'Post-' which means it comes after MySQL. So, it must be an upgraded and improved version!"
While I might have exaggerated (yes I have!) the conversation here - I personally have been dumbstruck by the same question - "Which SQL technology to use?". I would commend the Intern here to come up with a very creative if not the right answer. Hence this whole rant from now on is just trying to really understand what lines should one think around when making the same choice. So let's get started!
Going back to the basics!
The ultimate aim of having a database is to have a layer of durable persistence in your application which you can later query and get the results on. For that matter, even Google Sheets can act as your DB. So why do need such sophisticated software to achieve the simple task of saving and reading some data? Turns out if we want to consistently get the results in the same amount of time irrespective of the amount of data we store - these software really come in handy.
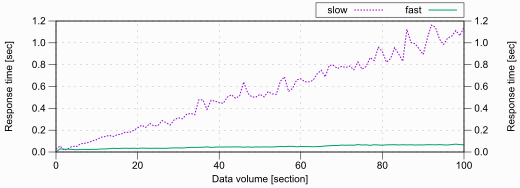
The graph above shows how an increase in data can easily increase the response time of the same query. Imagine people not being able to browse their favourite things on e-commerce websites - which they are never going to buy or mindlessly scrolling and double-tapping photos. (in retrospect slowing down it will be better for humanity, but will rant on this some other day)
Okay - so we need data and we need it fast. But to have durable persistence all our data is stored in disks - and they are slow. HDD or SSD when under pressure (looking for a particular row - or a set of rows) cannot provide data at the latencies that we aspire to achieve. So how do the current technologies go around these problems?
How is data managed internally?
All data irrespective of storage technology is stored as blocks of memory. These blocks are logically referred to as pages. (Page size and block size can be different). Each page contains a set of rows of a particular table. Hence the memory is not row-addressable but page addressable. Thus systems generally read the whole page than a particular row - hoping that some other query also might just need the same page and then we can refer it from the cache than asking the disk for it again and again.
The Ultimate Objective
The holy grail of any DBMS system is just trying to achieve the objective - "How can I minimise the number of pages I read from the disk for a particular operation - thus reducing Disk I/O - eventually reducing latency.
Take any complex concept like Sharding the DB, Partitioning the Table, or Adding complex indexing strategies - all of them are just trying to achieve the same. Let me go through an example to put this into perspective.
Imagine you have a table with 1 Million rows - which roughly translates to hypothetically 1000 pages and each page processing takes 1 second. For now, let's just say the DB does not support parallel processing using threads.
You run a query against it which requires a particular row - now what the DB would do is fetch all the 1000 pages read and filter the rows inside them till it finds the particular row you are looking for. Worst case scenario you take 1000s (assuming the row concerned was on the last page). Imagine if this was your order table - it's not going to work.
Now let's say you add an index to the column you are querying on - the internal structure of this index (B+Tree for example) will also need to be persisted and add additional pages - but since this involves a single column will lead to a small number of pages. Let's say we reduce it to 500 pages and the branching factor (how many children each node will have in the tree ) is 3 - now the DB will read log3(500)=~6 pages to reach the target page and then fetch the row from that page.
Now let's say we partition the table as well - so we divide the table as such that each partition has 100k rows and each partition will have its index. Now internally the query will be optimised as such that we will only want to concern with 1 partition which will eventually have a lesser index size coz rather than dealing with million rows, we only have 100k rows - hence less number of pages.
To further optimise the same thing now we will "shard" the table - which just means we will divide the table into different DBs and the client will be smart enough to know which shard or DB to call. Let's say each shard is dealing with only 100k rows approximately. Now you can see each shard will have a smaller number of rows - then the partition will further reduce the scope and so would the indexing strategy.
Each DB technology is literally or "figuratively" just trying to work this charm of reducing the scope of pages to be read at the heart of it. There are other concerns like ACID properties which mostly all SQL DB's adhere to which brings concurrency and transaction isolation into the picture as well. There is replication as well to handle higher loads of traffic - so that's also something we should think about.
Fundamental Tangents to Lookout for...
This section will try to surface some fundamental tangents that one can look at to understand any SQL system out there. This might not be an extensible list - but just something I have been able to achieve so far. They mostly try to see how each SQL technology in this universe is trying to achieve this ultimate objective!
Indexing Strategy
As we discussed above, indexing is one of the major strategies used by all databases out there to scan less number of pages - find what they need and depending on the query (unless it's not an index-only scan) fetch the required details from the main table and present it back to the client. Since indexes involve a very selective number of columns - hence the data set is small - so is the eventual number of pages required. Though this might entice you to add a lot of indexes and call it a day - but indexes by nature are redundant so they might make your query faster maintaining them during write will take the hit and also let's not forget about the extra space they would take on your disk. Hence we need to be very mindful of them.
Other than this, sometimes there are some under-the-hood nuances that one should look for - each database tends to make some trade-offs in the implementation to optimise a certain vector of performance. Having a good sense of these would help you in choosing the right tool for your project.
Let's take MySQL(with InnoDB) and PostgreSQL as an example and see how their implementation can affect different things:
At a high level, both PostgreSQL and MySQL utilize B+Trees as an index representation. This indexing structure organizes the data in a tree-like hierarchy, where each node in the tree contains a range of indexed values. As you navigate through the tree, following the path based on the indexed value you are searching for, you eventually reach the leaf nodes that hold the desired data. The B+Tree data structure efficiently supports operations such as insertion, deletion, and searching, making it well-suited for indexing in database systems. But it's what is at the leaf level that dramatically changes things.
At the leaf level of their B+Tree index structures, PostgreSQL uses direct pointers (RowId) to the physical location of the rows, while MySQL references the primary key values. This means that PostgreSQL can quickly retrieve the associated data, providing efficient data access. In contrast, MySQL requires an additional step of looking up the primary key to find the corresponding row, which introduces some overhead. This happens because of how data is organised internally - in MySQL tables generally are organised as an index (primary key) and leaf nodes are pointers to the actual pages which need to be read from the disk. You must think Postgres might have won here but there is something we need to be wary of - which comes in during the write/update path.
In PostgreSQL, an update to a row can result in changes to all indexes that reference that row, including the indexes on non-primary key columns. This primarily happens because in PostgreSQL each update is internally an insert (more on this in concurrency management) which changes the RowId and thus index needs to be updated. They optimise it with HOT updates but that has its shortcomings. In contrast, MySQL's InnoDB storage engine, which is the default engine for MySQL, utilizes a clustered index structure where the primary key determines the physical order of rows in the table. As a result, updates to non-primary key columns in MySQL may not necessarily require modifications to all indexes, as long as the primary key remains unchanged.
Thus what optimisations you might make during reading you'll have to pay it off during writing performance.
If you now feel that MySQL won the game in the last round - let me make it more interesting. Now the choice of Primary key in MySQL can easily bloat up your secondary indexes coz all of them refer eventually to the primary key.
So let's say you choose UUID as the primary key for your table - each secondary index leaf will refer to a 16-byte string in the end. So imagine this at the scale of storing 100k rows in your original table and having 4 indexes on that - I'll let you do the math. PostgreSQL no matter what you choose as the primary key - always assigns a row to reach the row created which does not cause this problem.
In Conclusion - though Indexing is a good way to get good performance from your DB having a sense of how things are handled under the hood will help you in taking the right call.
Transaction and Concurrency Management
Any SQL database needs transaction and concurrency management to ensure data integrity, and consistency and to handle concurrent access by multiple users or processes.
Transaction and concurrency management support the ACID properties (Atomicity, Consistency, Isolation, Durability) that guarantee reliable and robust database operations. ACID compliance ensures that transactions are all-or-nothing, maintains data integrity, and provides consistent and durable results, even in the face of failures or concurrent access.
They also play a crucial role in optimizing database performance and scalability. Effective concurrency control allows for the concurrent execution of multiple transactions, improving system throughput and responsiveness. Additionally, proper transaction management enables efficient resource utilization, reduces contention, and minimizes the need for costly rollbacks. Without concurrency management, simultaneous access to shared data can lead to conflicts and data inconsistencies. Concurrency control mechanisms ensure that concurrent transactions do not interfere with each other, preventing issues such as data corruption, lost updates, or inconsistent reads.
To summarise - In a world without concurrency and transaction management in SQL, it's like a bustling marketplace without any rules. Developers scramble to manage conflicting changes, while customers find themselves frustrated and unable to purchase their desired items from e-commerce websites. It's a chaotic scene where inventory counts fluctuate unpredictably, leaving customers with half-filled shopping carts and a sense of bewilderment. Queries clash like a clash of cymbals, resulting in inconsistent data and exasperated developers yearning for a more orderly system.
Let us again take PostgreSQL and MySQL as our candidates and see how internal implementations have performance ramifications
Transaction Management
PostgreSQL uses a multi-version concurrency control (MVCC) approach, where each transaction operates on a snapshot of the database, allowing concurrent read and write operations without blocking. This blog won't be able to cover the internals of it - but imagine it operates like a library with numerous editions of the same book. Each edition represents a different version of the data, capturing the state of the database at a specific point in time. For more details, you can refer here.
MySQL uses a different approach to handle concurrency called "locking." It utilizes a lock-based mechanism, where read and write locks are acquired on the data being accessed, preventing other transactions from modifying the same data until the lock is released.
Concurrency Management
PostgreSQL's MVCC model allows for a high degree of concurrency. It achieves this by maintaining multiple versions of each row, allowing readers to access the data without blocking writers and vice versa. PostgreSQL uses a combination of read and write locks to ensure consistency when necessary. This approach enables concurrent access to different parts of the database, resulting in better scalability and performance for read-heavy workloads.
MySQL's lock-based mechanism can sometimes lead to more contention and blocking in highly concurrent environments. When one transaction acquires a lock on a particular data item, other transactions may need to wait until the lock is released. This can result in decreased concurrency and potential performance issues, especially in scenarios with many write operations or long-running transactions.
Performance Impact
By acquiring exclusive locks, MySQL maintains strict control over data access, which can result in a more deterministic and predictable outcome. In contrast, PostgreSQL's MVCC system prioritizes concurrency by allowing multiple transactions to operate concurrently, but it may introduce some level of inconsistency depending on the isolation level chosen.
This generally comes down to the question of Pessimistic Concurrency Control vs Optimistic Concurrency Control. In the case of MySQL, locks have a pessimistic nature hence we can have a lot of waiting transactions if not handled properly (remember transactions can be read-only as well - so write can block reads) - but this is more predictable from a developer perspective hence we can control flow better. MVCC which is Postgres is more optimistic and says if something is not possible we'll just throw an error - which will now be the developer's responsibility to anticipate and retry accordingly.
SELECT * FOR UPDATE ... query.Replication Strategy
Replication in SQL systems, such as PostgreSQL, MySQL, Oracle, and Microsoft SQL Server, offers significant benefits in terms of scalability and availability. It enables horizontal scalability by distributing the workload across multiple servers, improves performance through load balancing, and facilitates geographic distribution to serve users in different regions efficiently. Read replicas, for example, can offload read queries from the primary server, enabling better utilization of resources and improved response times for read-intensive workloads.
Replication ensures high availability by providing redundancy and fault tolerance, allowing standby servers or replicas to take over in case of primary server failures. Additionally, it plays a crucial role in disaster recovery by maintaining copies of data in remote locations and ensuring business continuity in the face of hardware failures, network outages, or disasters.
Each SQL technology employs and provides a different set of replication strategies which at the core are either mutated or combined versions of primarily two replication strategies:
Asynchronous Replication: The primary database server sends the replication changes to the standby server(s) without waiting for the changes to be written to the disk. It can provide high write throughput on the primary server. However, there may be a potential for data loss if the primary server fails before the changes are replicated.
Synchronous Replication: The primary server waits for the standby server(s) to acknowledge the changes before committing them. It ensures data consistency but can introduce additional latency on the primary server. The transaction commit time increases as the primary server must wait for the slowest replica to acknowledge the changes.
Let us again take PostgreSQL and MySQL as our candidates and see how different internal implementations have performance ramifications:
Other than the above PostgreSQL provides a variant called Logical Replication allowing selective replication of specific tables or database objects which can provide more flexibility in terms of replication granularity, but it introduces some overhead due to the need for capturing and propagating logical changes. Similarly, MySQL has Semi-Synchronous Replication where the master server waits for at least one slave to acknowledge the changes before committing.
PostgreSQL's streaming replication and logical replication offer flexibility and high performance but may have potential data loss or overhead. MySQL's asynchronous and semi-synchronous replication provide scalability but may introduce latency.
Now right now this might seem like basic stuff but just combine it with things we learnt during the indexing strategy. We observed that an update of a row in Postgres can lead to updating all the indexes which exist on the table - now imagine all of these changes need to be replicated across your replicas. We might have just made a single change but internally that can be way more number writes (this is generally known as write amplification) - this would have a huge impact on the choice of replication strategy coz once a replica is not able to catchup with your primary DB - all read operations on that DB might work with stale data. Hence developing these fundamentals can help you foresee the ramifications of your changes way before you experience them in production and if you experience them you know how to navigate around them.
Concluding thoughts and what's next!
By no nature, this list covers all the vectors but I feel will give a good starting point - if you're confused than sorted after reading this then don't worry - trust me that is the best place to be because once you go down this rabbit hole, you'll come out "a less bad" version of you (embrace the confusion, trust me I am on the same journey), maybe the Intern at the start of the blog will hire you since they still need one more job to be filled and a whole project to be finished.
As an extension to this blog, I'll try and map all of these fundamentals on a technology I have been looking to study "Cockroach DB" which might be handling everything differently but at its core is just trying to achieve the same - just let me read the most minimum amount of data coz disk is expensive.


